

I figured out how RNN works and I was so happy to understand this kind of ANN till I faced the word of recursive Neural network and the question arose that what is differences between Recursive Neural network and Recurrent Neural network.
Now I know what is the differences and why we should separate Recursive Neural network between Recurrent Neural network. In this post I am going to explain it simply.
The best way to explain Recursive Neural network architecture is, I think, to compare with other kinds of architectures, for example with RNNs:
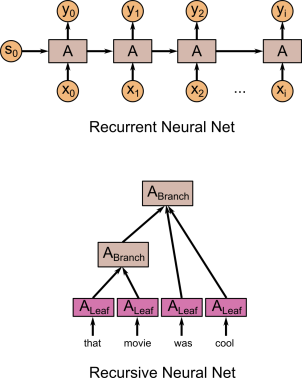
Recursive Neural network
is quite simple to see why it is called a Recursive Neural Network. Each parent node's children are simply a node similar to that node.
Recursive neural networks comprise a class of architecture that can operate on structured input. They have been previously successfully applied to model compositionality in natural language using parse-tree-based structural representations. Even though these architectures are deep in structure, they lack the capacity for hierarchical representation that exists in conventional deep feed-forward networks as well as in recently investigated deep recurrent neural networks. In this work we introduce a new architecture — a deep recursive neural network (deep RNN) — constructed by stacking multiple recursive layers. We evaluate the proposed model on the task of fine-grained sentiment classification. Our results show that deep RNNs outperform associated shallow counterparts that employ the same number of parameters. Furthermore, our approach outperforms previous baselines on the sentiment analysis task, including a multiplicative RNN variant as well as the recently introduced paragraph vectors, achieving new state-of-the-art results. We provide exploratory analyses of the effect of multiple layers and show that they capture different aspects of compositionality in language. you can read the full paper.
If you are interested to know more how you can implement Recurrent Neural Network , Go to this page and start watching this tutorial.
Recurrent Neural network
The idea behind RNNs is to make use of sequential information. In a traditional neural network we assume that all inputs (and outputs) are independent of each other. But for many tasks that’s a very bad idea. If you want to predict the next word in a sentence you better know which words came before it. RNNs are called recurrent because they perform the same task for every element of a sequence, with the output being depended on the previous computations. Another way to think about RNNs is that they have a “memory” which captures information about what has been calculated so far. In theory RNNs can make use of information in arbitrarily long sequences, but in practice they are limited to looking back only a few steps (more on this later). Here is what a typical RNN looks like:
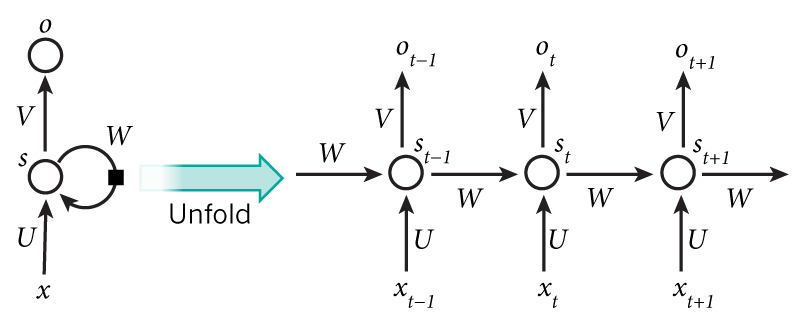
The above diagram shows a RNN being unrolled (or unfolded) into a full network. By unrolling we simply mean that we write out the network for the complete sequence. For example, if the sequence we care about is a sentence of 5 words, the network would be unrolled into a 5-layer neural network, one layer for each word. The formulas that govern the computation happening in a RNN are as follows:
- x_t is the input at time step t. For example, x_1 could be a one-hot vector corresponding to the second word of a sentence.
- st is the hidden state at time step t. It’s the “memory” of the network. s_t is calculated based on the previous hidden state and the input at the current step: s_t=f(Ux_t + Ws_{t-1}). The function f usually is a nonlinearity such as tanh or ReLU. s{-1}, which is required to calculate the first hidden state, is typically initialized to all zeroes.
- o_t is the output at step t. For example, if we wanted to predict the next word in a sentence it would be a vector of probabilities across our vocabulary. o_t = \mathrm{softmax}(Vs_t).
There are a few things to note here:
You can think of the hidden state s_t as the memory of the network. s_t captures information about what happened in all the previous time steps. The output at step o_t is calculated solely based on the memory at time t. As briefly mentioned above, it’s a bit more complicated in practice because s_t typically can’t capture information from too many time steps ago.
Unlike a traditional deep neural network, which uses different parameters at each layer, a RNN shares the same parameters (U, V, W above) across all steps. This reflects the fact that we are performing the same task at each step, just with different inputs. This greatly reduces the total number of parameters we need to learn.
The above diagram has outputs at each time step, but depending on the task this may not be necessary. For example, when predicting the sentiment of a sentence we may only care about the final output, not the sentiment after each word. Similarly, we may not need inputs at each time step. The main feature of an RNN is its hidden state, which captures some information about a sequence.
Refrence:
1.http://www.cs.cornell.edu/~oirsoy/drsv.htm
2.https://www.experfy.com/training/courses/recurrent-and-recursive-networks
3.http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/
Comments