

I have read 5 articles that have worked on Network of Experts, and I want to share some important part of this papers that I've found it super cool.
Network of Expert
A tree-structured network architecture for large-scale image classification that can classify most similar and confusing classes in high accuracy.
The full article that I am going to talk about is here. Network of Experts for Large-scale image categorization.
The trunk of the network contains convolutional layers optimized over all classes. At a given depth, the trunk splits into separate branches, each dedicated to discriminate a different subset of classes. Each branch acts as an expert classifying a set of categories that are difficult to tell apart, while the trunk provides common knowledge to all experts in the form of shared features. The training of our “network of experts” is completely end-to-end: the partition of categories into disjoint subsets is learned simultaneously with the parameters of the network trunk and the experts are trained jointly by minimizing a single learning objective over all classes. The proposed structure can be built from any existing convolutional neural network (CNN). The paper demonstrate its generality by adapting 4 popular CNNs for image categorization into the form of networks of experts. They worked on CIFAR100 and ImageNet.
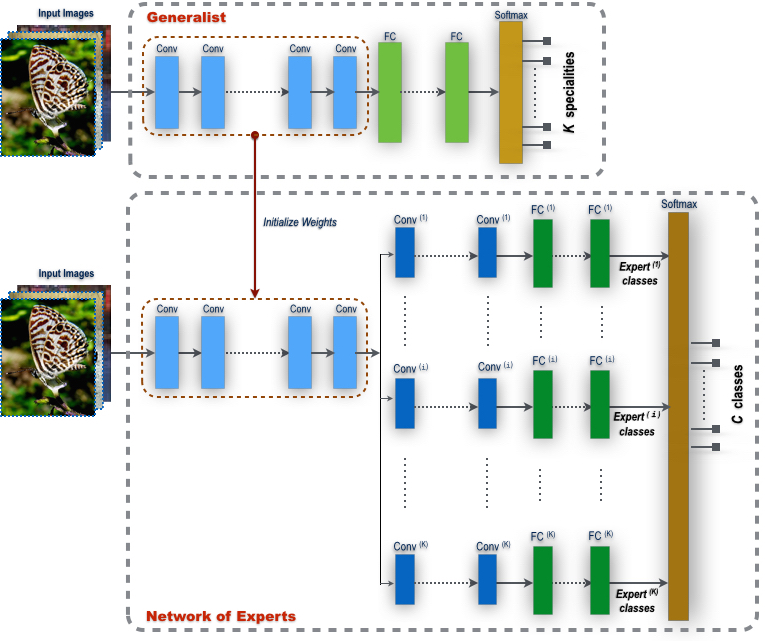
Fig. 1. Our Network of Experts (NofE). Top: Training of the generalist. The generalist is a traditional CNN but it is optimized to partition the original set of C classes into K << C disjoint subsets, called specialties. Our method performs joint learning of the K specialties and the generalist CNN that is optimized to recognize these specialties.
Bottom: The complete NofE with K expert branches. The convolutional layers of the generalist are used as initialization for the trunk, which ties into K separate branches, each responsible to discriminate the classes within a specialty. The complete model is trained end-to-end via backpropagation with respect to the original C classes.
Although the learning scheme involves two distinct training stages – the first aimed at learning the generalist and the specialties, the second focused on training the experts – the final product is a unified model performing multiclass classification over the original classes, which we call “Network of Experts” (NofE). The training procedure is illustrated in Fig 1. The generalist is implemented in the form of a convolutional neural network (CNN) with a final softmax layer over K specialties, where K << C, with C denoting the original number of categories (Figure 1(top)).
After this first training stage, the fully connected layers are discarded and K distinct branches are attached to the last convolutional layer of the generalist, i.e., one branch per specialty. Each branch is associated to a specialty and is devoted to recognize the classes within the specialty. This gives rise to the NofE architecture, a unified tree-structured network (Figure 1(bottom)). Finally, all layers of the resulting model are finetuned with respect to the original C categories by means of a global softmax layer that calibrates the outputs of the individual experts over the C categories.
So, another question comes to my mind that Why should have generalist? when we can use the Network of Expert directly.
the learning of our generalist serves two fundamental purposes:
First, using a divide and conquer strategy it decomposes the original multiclass classification problem over C labels into K subproblems, one for each specialty. The specialties are defined so that the act of classifying an image into its correct specialty is as accurate as possible. At the same time this implies that confusable classes are pushed into the same specialty, thus handing off the most challenging class-discrimination cases to the individual experts. However, because each expert is responsible for classification only over a subset of classes that are highly similar to each other, it can learn highly specialized and effective features for the subproblem, analogously to a human expert identifying mushrooms by leveraging features that are highly domain-specific (cap shape, stem type, spore color, flesh texture, etc.).
second, the convolutional layers learned by the generalist provide an initial knowledge-base for all experts in the form of shared features. In our experiments we demonstrate that fine-tuning the trunk from this initial configuration results in a significant improvement over learning the network of experts from scratch or even learning from a set of convolutional layers optimized over the entire set of C labels. Thus, the subproblem decomposition does not merely simplify the original hard classification problem but it also produces a set of pretrained features that lead to better finetuning results.
Comments